Benchmarking constraint inference in inverse reinforcement learning
Introducing an ICRL benchmark in the context of RL application domains.
G Liu, Y Luo, A Gaurav, K Rezaee, P Poupart
abstract
agents unaware of
underlying constraints ← hard to specify mathematically
inverse constrained reinforcement learning (ICRL)
estimates from expert demonstrations
introduction
constrained reinforcement learning (CRL)
learns policy under some known or predefined constraints
not realistic in real-world → hard to specify exact constraints
infer from expert demonstrations
ICRL
infers a constraint function to approximate constraints respected by expert demonstrations
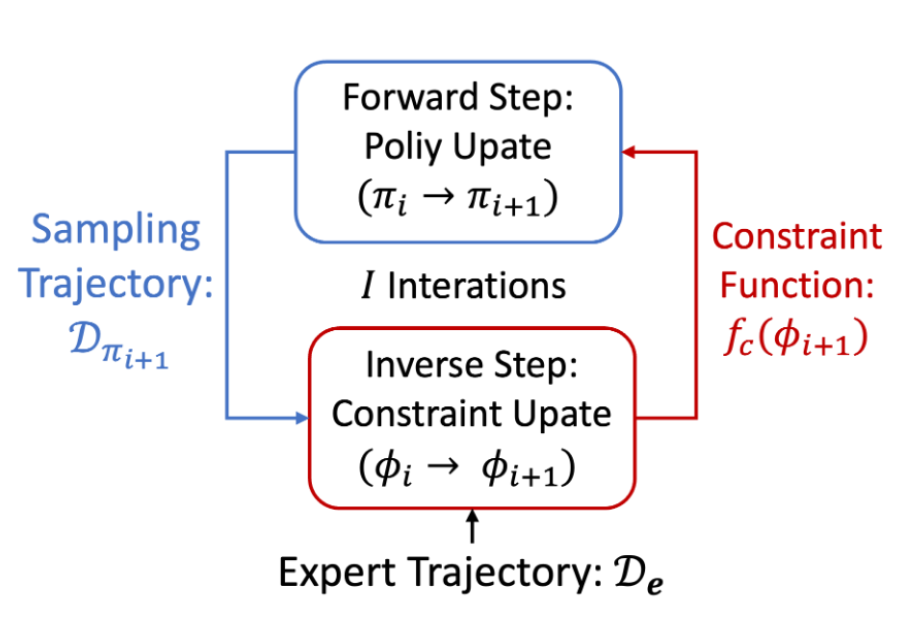
alternating between updating
imitating policy
constraint function
contributions:
- expert demonstrations might violate constraint
- under stochastic environment
- muultiple constraints
- recovering the exact least constraining constraint
background
constrained reinforcement learning
based on constrained markov decision processes (CMDPs)
to learn policy under cmdp, consider following optimization
cumulative constraints
where denotes the policy entropy weighted by
commonly used in soft setting → recover from undesirable movement i.e. high cost
discounted additive cost less than the threshold
trajectory-based constraints (alternative approach)
defining constraints w/o relying on discounted factor
where is the tracjectory cost
depending on how is defined, we can get more restrictive constraints than cumulative
for example,
where indicates the prob
performing a under s is safe
stricter than additive cost
inverse constraint inference
in practice
no constraints but expert demonstrations that follow constraints
goal
agent recover constraint from dataset
challenge
different reward & constraint combination
for identifiability
ICRL assumes rewards are observable
goal
recover the minimum constraint set that best explains expert data
key difference from IRL
IRL learns reward from unconstrained MDP
maximum entropy constrain inference
where
- denotes # of trajectories in the demonstration dataset
- normalizing term
- indicator . can be defined by and defines to what extent the trajectory is feasible
ICRL can be formulated as a bi-level optimization problem that iteratively updates
upper-level objective
policy optimization
lower-level objective
constraint learning until convergence
matches expert policy