abstract
inverse constraint reinforcement learning (icrl)
recover the underlying constraints
existing algorithms assume single type of agent
challenging to explain why unified constraint function
multi-modal inverse constrained reinforcement learning (MMICRL)
different types of experts
flow-based density estimator
unsupervised expert identification
novel multi-modal constrained policy optimization
minimizes agent-conditioned policy entropy
maximizes the unconditioned one
contrastive learning framework ← enhance robustness
capture diversity
introduction
problematic to leverage one single constraint model
previously to differentiate expert demonstrations
inferred the latent structure of expert demonstrations
identified by behavioral preferences
no theoretical guarantee that optimal model is identifiable
contributions
-
unsupervised agent identification
flow-based density estimator
each agent’s policy must correspond to a unique occupancy measure
-
agent-specific constraint inference
using the identified demonstrations
estimates a permissibility function → construct constraints for each type of agent
-
multi-modal policy optimization
comparing the similarity between
expert trajectories
generated ones by imitation policies under inferred constraints
treat generated trajectories as
noisy embeddings of agents
enhance similarity between embeddings for agents of the same type
problem definition
constrained mixture-agent markov decision process
CMA-MDP Mϕ
(S,A,Z,R,pτ,{(pci,ϵi)}∀i,γ,μ0)
Z denotes the latent code (for specifying expert agents)
in contrast to multi-agent reinforcement learning (MARL)
multiple agents act concurrently
do not distinguish agent types, policies, and constraints
cma-mdp allows
only one agent to operate at a given time
policy update under conditional constraints
constrained reinforcement learning (CRL)
goal → max reward under conditional constraints
J(π∣z)=πmaxEμ0,pτ,π[t=0∑Tγtrt]+βH(π) s.t. Eτ∼(μo,pτ,π),pcj[cj(τ∣z)]≤ϵj(z) ∀j∈[0,J]
where
H(π) denotes policy entropy weighted by β
c(τ∣z)=1−Π(s,a)∈τϕ(s,a∣z) denotes trajectory cost
ϕ(s,a∣z) denotes permissibility function that indicates the prob. performing action a under state s is safe for agent z
assumes constraints are known
instead, we only have
expert demonstrations that follow the underlying constraints
therefore, agents must recover the constraints
constraint inference from a mixture of expert dataset
p(DE∣ϕ)=ZMc^ϕ1Πi=1Nz∑1τi∈Dzexp[r(τ(i))]1Mc^ϕ(τ(i)∣z)
where
N denotes # of trajectories in the demonstration dataset
ZMc^ϕ denotes a normalizing term
1Mc^ϕ(τ(i)) denotes permissibility indicator and can be defined by
ϕ(τ(i)∣z)=Πt=1Tϕt(sti,ati∣z)
1τ(i)∈Dz denotes whether the trajectory τ(i) is generated by the agent z (agent identifier)
icrl for a mixture of experts
mmicrl
- exhibit high entropy when agent type is unknown
-
collapse to a specific behavioral mode when type is determined
low entry when agent type is known
Minimize −α1H[π(τ)]+α2H[π(τ∣z)]Subject to ∫π(τ∣z)fz(τ)dτ=N1τ∈Dz∑f(τ)∫π(τ∣z)dτ=1∫π(τ∣z)logϕ(τ∣z)dτ≥ϵ
where
f(⋅) denotes a latent feature extractor
objective differs from traditional maximum entropy rl in two ways
- minimizes an entropy conditioned on agent types
- additional constraint related to policy permissibilty
Proposition LET p(z∣τ) denote the trajectory-level agent identifier, let r(τ)=α2−α1λ0f(τ) denote the trajectory rewards, let ZMc^ϕ denote a normalizing term. The optimal policy of the above optimization problem can be represented as
π(τ∣z)=ZMc^ϕ1exp[α2−α1α1Ez∼p(z)[log(p(z∣τ))]+r(τ)]ϕ(τ∣z)α1−α2λ2
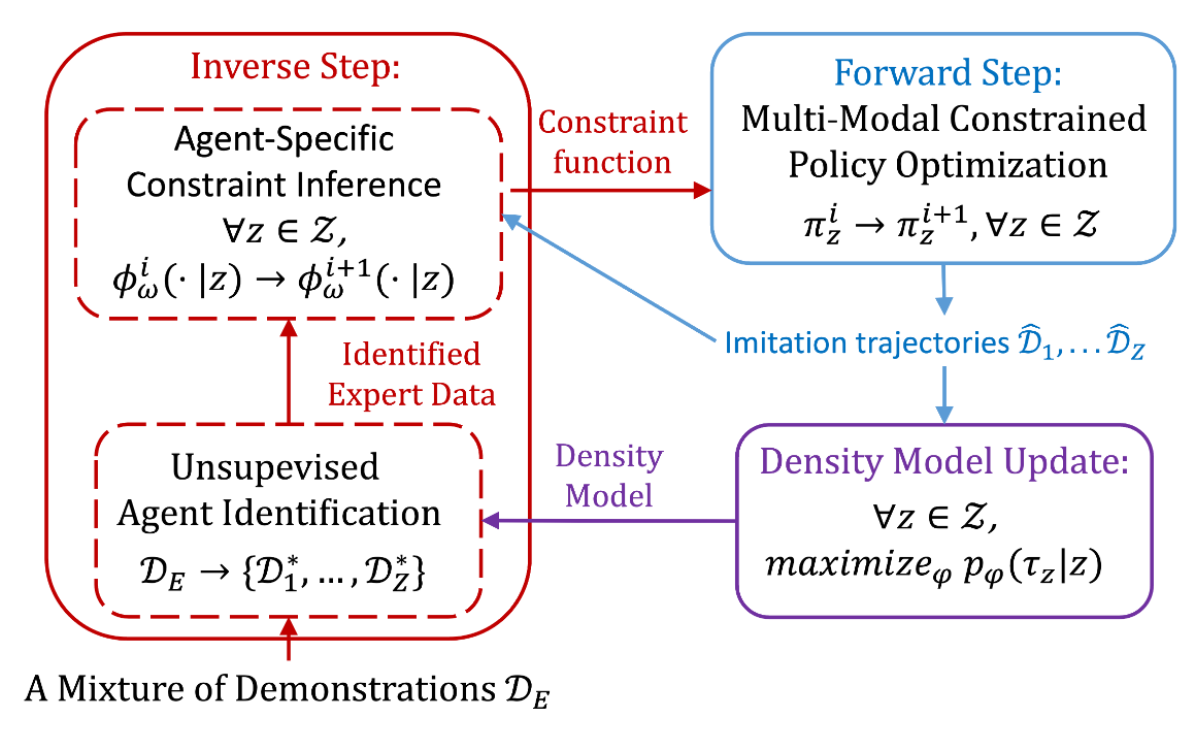
kep iterative steps of mmicrl
- unsupervised agent identification for calculating p(z∣τ)
- conditional inverse constraint inference for deducing ϕ(τ∣z)
- multi-modal policy update for approximating π(τ∣z)
mmicrl alternates between these steps until
imitation policies reproduce expert trajectories
question: what if expert trajectories violates the underlying constraints as well?
unsupervised agent identification
mmicrl performs
trajectory level agent identification
state action density
ρπ(s,a)=(1−γ)π(a∣s)∑t=0∞γtp(st=s∣π) where p(st=s∣π) is the probability density of state $s$ at time step $t$ following policy π
Proposition 4.2. Suppose ρ is the occupancy measure tha satisfies the Bellman flow constraints: ∑aρ(s,a)=μ0(s)+γ∑s′,aρ(s′,a)Pτ(s′∣s,a) and ρ(s,a)≥0. Let the policy defined by πρ(a∣s)=∫ρ(s,a′)da′ρ(s,a), then πρ is the only policy whose occupancy measure is ρ.
Bellman Flow Constraint is defined as
χ(s,a)=π(a∣s)⋅[(1−γ)μ0(s)+γ∫χ(s′,a′)τ(s∣s′,a′)ds′d′];χ(s,a)≥0
It can be shown that occupancy measure ρπ(s,a) is a unique solution to Bellman flow constraint
Density Estimation
“one can identify an expert agent by examining the occupancy measures in the expert trajectories”
conditional Flow-based Density Estimator (CFDE)
extimates the density of input variables in the training data distribution under an auto-regressive constraint
conditions on agent types
the function ψ is implemented by stacking multiple MADE layers
p(xi∣x1:i−1,z)n=N(xi∣μi,(exp(αi))2) where μi=ψμi(x1:i−1,z) and αi=ψαi(x1:i−1,z)
pψ(z∣τ)=∑z′Π(s,a)∈τpψ(s,a∣z′)Π(s,a)∈τpψ(s,a∣z)
Agent Identification
add τi to Dz if z=argmaxz∑(s,a)∈τilog[pψ(s,a∣z)]
agent-specific constraint inference
∇ωlog[p(Dz∣ϕ,z)]:=i=1∑N[∇ϕ∑Tt=0ηlog[ϕω(st(i),at(i)∣z)]]−NEτ^∼πMϕ(⋅∣z)[∇ϕt=0∑T[ηlog[ϕωs^t,a^t∣z)]]
multi-modal policy optimization
the multi-modal policy optimization object
πmin−Eπ(⋅∣z)[t=1∑Tmγtr(st,at)]−α1H[π(τ)]+α2H[π(τ∣z)]s.t. Eπ(⋅∣z)(t=0∑hγtlogϕω(s,a,z))≥ϵ
learning diverse policies via contrastive estimation
directly augmenting rewards lead to sub-optimal policy
a large penalty to trajectories with log pψ(z∣τ)
more sensitive to dense estimation rather than reward signals
replace the identification probability with a contrastive estimation method
πmin−Eπ(⋅∣z)(r(τ)+α1Lce(τ,V1,…,∣Z∣))+(α2−α1)H(π(τ∣z)) s.t. Eπ(⋅∣z)(t=0∑hγtlogϕω(s,a,z))≥ϵ
where Z is the probing sets
using sets generated by CFDE
Lce(τ,V1,…,∣Z∣)=t=0∑Tlog∑z~∈Zexp[∑(a^,a^)∈Vz~fs[(st,at),(s^,a^)]]exp[∑(s^z,a^z)∈Vzfs[(st,at),(s^t,a^t)]]
where $f_s$ denotes the score function for measuring the similarity between different state-action pairs using cosine similarity
(s,a)∈{τ,Vz} → positive embeddings for π(⋅∣z)
(s~,a~)∈{Vz~}z~=z → negative embeddings for π(⋅∣z)
consider generation as injecting environmental noise into the policy
since Vz belongs to high-conditional density region in p(⋅∣z)
knowledge from density estimator is integrated into policy updates